Run a basic word count map reduce program to understand map reduce paradigm

Greetings, I'm Ashwin Santosh Telmore, a passionate tech enthusiast on a mission to demystify the intricate world of technology. With a background in Computer Engineering and a flair for simplifying the complex, I'm here to share tech knowledge in the easiest and most accessible way.
Imagine having your own personal tech guide – that's where I come in! From exploring the wonders of the MERN stack to unraveling the magic behind web development, I'm here to make tech concepts like C++, JavaScript, and Python a walk in the park.
Navigating the dynamic realm of web technologies, I've mastered HTML, CSS (SASS), and JavaScript, empowering me to bring websites to life with interactivity. Let's embark on a journey through the ever-evolving tech landscape, making the intricate world of technology understandable for all.
Java code Create a .java file and paste following code
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Run this following command
export $HADOOP_CLASSPATH=$(hadoop classpath)
Create the data.txt file and paste this following code into it
my
name
is
ashwin
i
repeat
my
name
is ashwin
create input directory on hadoop
hadoop fs -mkdir /user/ashwin/input
upload this file to the hadoop
hadoop fs -put data.txt /user/ashwin/input
create output directory on hadoop
hadoop fs -mkdir /user/ashwin/output
Run java file
javac -classpath ${HADOOP_CLASSPATH} -d /<class_folder> /<path_java_file>
convert to .jar file
jat -cvf jar_file_name.jar -C /<class_folder> /<path_to_be_store>
Enter the command
hadoop jar jar_file_name.jar <Class_Name> /user/ashwin/input /user/ashwin/output
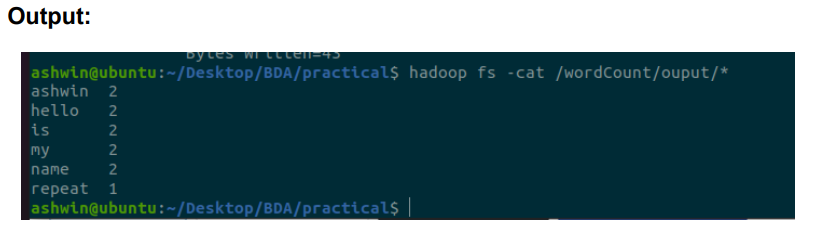
Final Output here